
The AI Partnership Race
A look at how Internet-age companies are partnering with AI startups for (1) research, (2) distribution, and (3) hardware.
Why? Because large companies can’t innovate the way startups can.
Slow product cycles from layers of bureaucracy
Extreme reputation risk (when things inevitably go wrong)
Disruption to existing business models (e.g., Search)
Distribution to a small but important new audience (e.g., LLM builders)
Incentives to make risky bets (e.g., startup equity)
Research
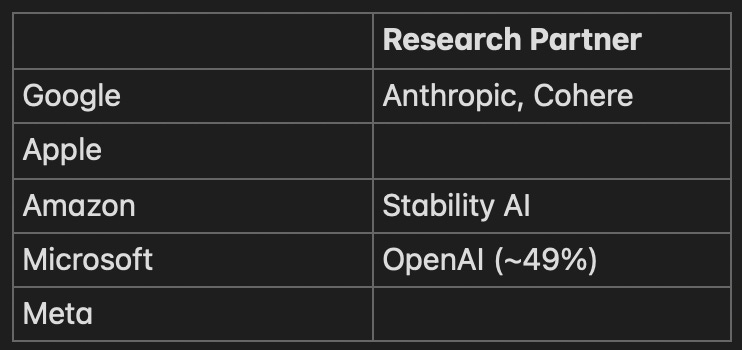
While all these companies have research organizations (Google researchers wrote the Transformers paper), there’s an inherent risk to productionizing these models. They could output incorrect, biased, or otherwise damaging information. They might train on the wrong data or bring up privacy concerns (a death sentence for companies already under intense public scrutiny). The startups gain some proprietary distribution for their models, but most importantly, access to the hardware and cloud resources they need to train foundational models.
Distribution

Distribution is all you need (right?). These companies defined distribution, so why would they need partners? While the field is still nascent, it’s essential to get the technology into the hands of the right people. That means (1) developers, (2) startups building the next big thing (3) and data scientists and machine learning practitioners. Startups that are hyper-focused on creating a dense community of these personas can beat the hyper-scaled companies that have to do everything. The partners can then access the foundational models and state-of-the-art research (e.g., OpenAI Codex / GitHub Copilot) to build differentiated products.
Hardware

Right now, access to GPUs is scarce. Startups fight to request quota on the cloud providers (and others, building their own data centers). At the lowest level, many of these models are tightly coupled to the underlying hardware, and I believe we’ll only see more application-specific chips (read: transformer-optimized architectures). Cloud hyper-scalers have started building this ability over the last few years, and Google and Apple have done so via chips for mobile. Even Meta has built out this capability with its partnerships in VR headsets. For what it’s worth, Meta has also worked to abstract the underlying GPUs (re: commoditize) out of PyTorch.
I left NVIDIA out of this, as it seems like they aren’t restricting themselves to a single cloud provider and are even moving up the stack via open-source.
Hey Matt, great post as always. I would like to know your thoughts on model defensibility. Right now, it seems everyone is focused on creating InstructGPT like responses via finetuning open source models and I am curious whether you think it's a fad or something that can actually threaten proprietary models.