
Deterministic, Structured LLM Completions
How do you consume text generated by LLMs with code? You might try prompt engineering to “format the answer in JSON”, but that won’t work all the time. Or you might try a variety of tricks to extract the answer or the field out of the text generation, but that’s also prone to error.
I’m launching another API on thiggle that lets you perform text generation with LLMs but with generated tokens conforming to regex patterns. That means that you can easily specify the shape of outputs — are they alphanumeric strings? Are they phone numbers? Email addresses? And the model will never output tokens that don’t match the regex pattern (even with the most sophisticated prompt engineering attacks).
The general idea is to modify the token distribution at runtime so that the generated output fits the regex patterns. It’s a similar idea to a library I open-sourced a few months ago called ReLLM (which has now found its way into llama.cpp, LangChain, and more). While open-source is great — you can’t use a library like this with off-the-shelf LLMs, and no hosted providers offer this feature. So I made it simple to use if you can’t self-host and modify your own models. Get started on GitHub.
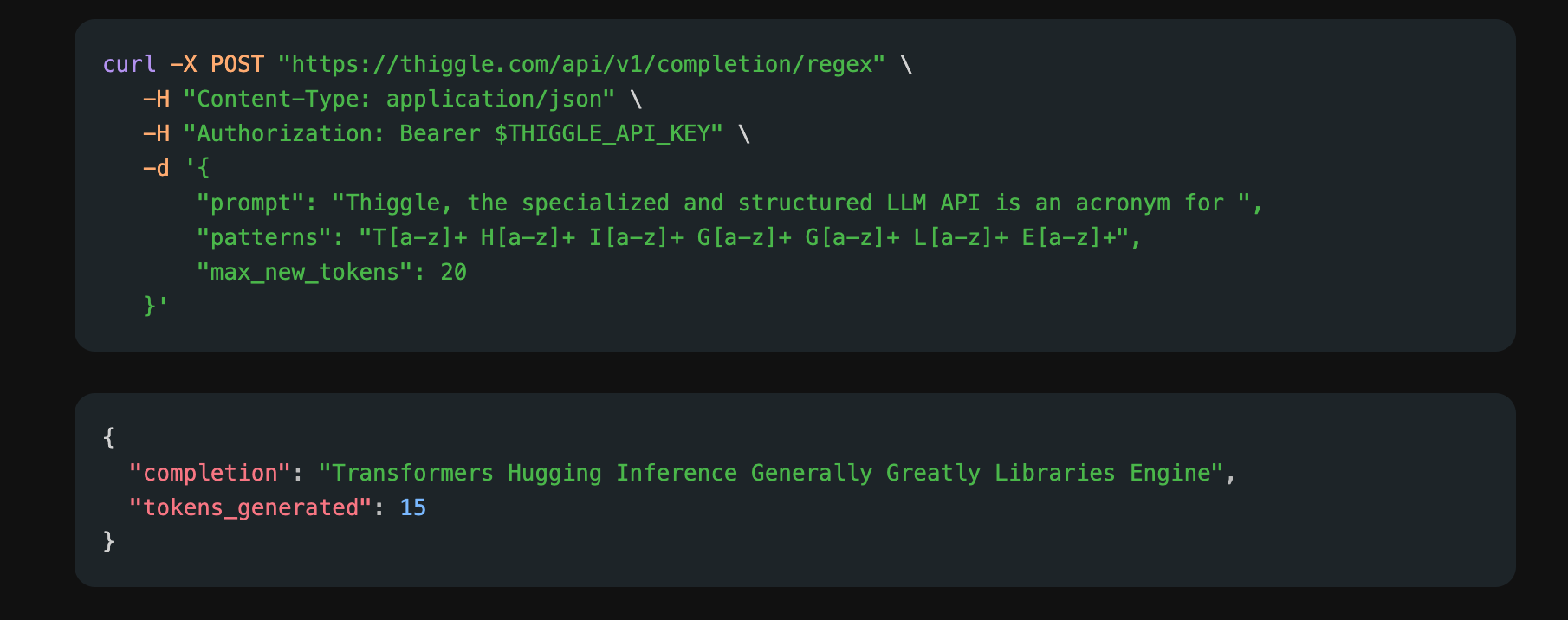
Here’s an example of how it works. We'll use the prompt "Thiggle, the specialized and structured LLM API is an acronym for " and a regex pattern to generate the acronym. We'll also set max_new_tokens to 20 to limit the output to 20 tokens. The regex pattern that corresponds to a potential acronym is T[a-z]+ H[a-z]+ I[a-z]+ G[a-z]+ G[a-z]+ L[a-z]+ E[a-z]+.
This is an example using cURL (there are also client libraries in Go, Python, and TypeScript):
Give it a try, and let me know your feedback. If you’re interested in running it with a larger or custom model or on dedicated hardware, let me know as well.