
Categorization and Classification with LLMs
So many tasks are classification tasks in disguise.
Answering multiple-choice questions
Sentiment analysis
Choosing the best tool(s) for an AI agent
Labeling training data
LLMs are excellent reasoning engines. But nudging them to the desired output is challenging. They might return categories outside the ones that you determined. They might return multiple categories when you only want one (or the opposite — a single category when you want multiple). Even if you steer the AI toward the correct answer, parsing the output can be difficult. Asking the LLM to output structure data works 80% of the time. But the 20% of the time that your code parses the response fails takes up 99% of your time and is unacceptable for most real-world use cases.
I’m releasing a specialized LLM API to solve all of these problems. With a prompt and categories, the API will always return structured data and the relevant categories. No more parsing the output manually or loading the prompt with tricks to coerce it into maybe outputting valid JSON. It’s simple to use, and I’ve written some simple zero-dependency clients in Python, Go, and TypeScript (of course, you can call the API directly via something like cURL).
Here’s an example that answers a simple multiple-choice question with multiple correct answers.
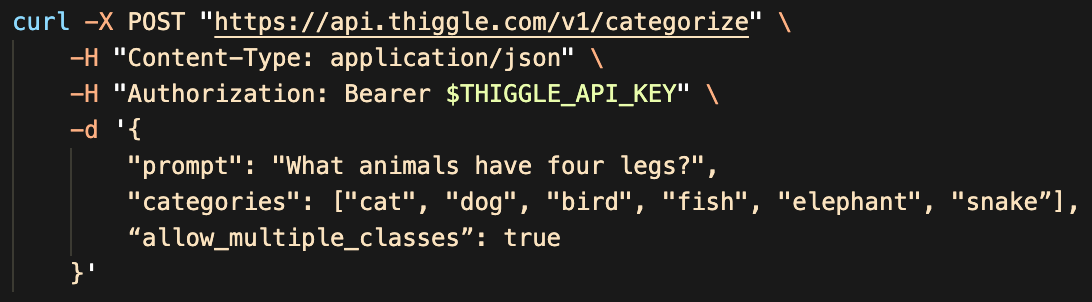
Which returns the JSON with only the selected categories.

Of course, you can do much more advanced queries — answering questions with a single answer or possibly no answer. A few ways I’ve been using this API internally
Label Training Data. In cases where you might use a human-based service to label data like Mechanical Turk, this is a much faster and cost-effective way to label large amounts of training data.
Building block for AI Agents. An essential task in building AI agents is tool selection. Agents are given a query and first must figure out what tools to use to complete the query. Right now, this is prone to multiple errors. The fix is usually like retrying (slow and expensive) until the LLM returns something that can be parsed. The categorization API won’t solve AI agents or AGI, but it provides a tiny building block to make agent frameworks more reliable.
Multiple-choice Questions / Decision Trees. A more generalized version of tool selection is answering multiple-choice questions or navigating decision trees. When you know the constrained set of choices (e.g., a chess-playing AI that generates a top list of next-move candidates), you can utilize LLMs much more than if they had the entire universe of selections.
Sentiment analysis. Plenty of specialized models will analyze sentiment, but most are finely tuned on common positive/negative classes. LLMs can categorize any set of sentiments — moods, positive/negative on a spectrum (e.g., slightly/very/extremely), or any other combination you can think of. Also suitable for labeling training data in this manner.
Give it a try: github.com/thiggle/api (documentation at docs.thiggle.com). What is “thiggle”? It’s a place I’ll be putting some of my LLM APIs that I’ll be releasing (the categorization API is the first). Client-side LLMs like chat.matt-rickard.com are great, but hosted LLMs can utilize much bigger models and unlock new use cases first.
Let me know your thoughts and other ideas about what you can do with the API.
Hey Matt, just curious - are we seeing a new product/company from you or is this just a project?
Can you speak regarding your technical approach to data structuredness server-side here (or is it secret)?